In questo articolo vogliamo presentare al lettore alcune domande sul Machine Learning che vengono poste ai colloqui di lavoro per verificare la preparazione del candidato. Le risposte sono relativamente brevi e immediate e vanno viste più come un test di ripasso per verificare la propria compressione e non come un strumento di studio in sé e per sé. Buona Lettura!
Table of Contents
- 1. COS’È IL MACHINE LEARNING?
- 2. QUANTI TIPI DI MACHINE LEARNING ESISTONO?
- 3. COS’È L’APPRENDIMENTO SUPERVISIONATO?
- 4. COS’È L’APPRENDIMENTO NON SUPERVISIONATO?
- 5. COS’È L’APPRENDIMENTO PER RINFORZO?
- 6. COS’È IL DEEP LEARNING?
- 7. COS’È UNA RETE NEURALE?
- 8. COS’È LA CLASSIFICAZIONE E LA REGRESSIONE NEL MACHINE LEARNING?
- 9. COS’È IL SELECTION BIAS?
- 10. COS’È UNA MATRICE DI CONFUSIONE?
- 11. COS’È L’APPRENDIMENTO INDUTTIVO E DEDUTTIVO?
- 12. COS’È IL KNN E IL K-MEANS CLUSTERING?
- 13. COS’È LA CURVA ROC?
- 14. QUAL È LA DIFFERENZA TRA ERRORE DI TIPO I E TIPO II?
- 15. CHE COSA SONO I FALSI POSITIVI/NEGATIVI ?
- 16. E’ PIU’ IMPORTANTE LA PERFORMANCE DEL MODELLO O LA SUA ACCURANCY?
1. COS’È IL MACHINE LEARNING?
Il Machine Learning è una branca dell’intelligenza artificiale che permette ai sistemi di apprendere automaticamente dai dati e migliorare le proprie prestazioni senza essere esplicitamente programmati. L’obiettivo principale del machine learning è accedere e analizzare i dati per prendere decisioni senza l’intervento umano. Ne sono un esempio i sistemi di raccomandazione su piattaforme come Netflix, che utilizzano il machine learning per suggerire film e serie TV basandosi sulle preferenze degli utenti.
2. QUANTI TIPI DI MACHINE LEARNING ESISTONO?
Esistono tre macro categorie di machine learning:
- Apprendimento Supervisionato (Supervised Learning):
- Gli algoritmi apprendono da dati etichettati, ossia dataset che contengono sia l’input che l’output desiderato.
- Esempio: classificazione di email nella nostra posta elettronica come “spam” o “non spam”.
- Apprendimento Non Supervisionato (Unsupervised Learning):
- Gli algoritmi in questo caso cercano di trovare strutture nascoste nei dati non etichettati. Saranno loro dunque a dover fornire l’output.
- Esempio: clustering di clienti in base ai comportamenti di acquisto.
- Apprendimento per Rinforzo (Reinforcement Learning):
- Qui gli algoritmi apprendono attraverso tentativi ed errori, ricevendo ricompense o penalità per le loro azioni.
- Esempio: addestramento di “agenti” per giocare a scacchi o a Go. L’esempio più famoso è forse il “campione di scacchi” DeepBlue!
3. COS’È L’APPRENDIMENTO SUPERVISIONATO?
Nell’apprendimento supervisionato, il modello viene addestrato utilizzando un set di dati etichettati, dove ogni esempio di addestramento è composto da un input e un output desiderato. Grazie agli algoritmi supervisionati riusciamo a scoprire le relazioni esistenti tra i dati e gli e la variabile target. Questo metodo viene utilizzato per problemi di classificazione e regressione. Ad esempio, per riconoscere frutti di diverse forme e colori, un sistema viene addestrato con immagini etichettate dei frutti stessi. Gli algoritmi si dividono in quelli appartenenti alla Regressione (Linear Regreassion e Random Forest) e quelli di Classificazione (Logistic Regression, Neural Network)
4. COS’È L’APPRENDIMENTO NON SUPERVISIONATO?
Nell’apprendimento non supervisionato, il modello non riceve etichette nei dati di addestramento e deve identificare strutture e trend autonomamente, esplorando nelle tabelle dei pattern, degli schemi che mostrano come righe e colonne siano collegate. Questo approccio è utilizzato per il clustering e l’analisi di associazione. Un esempio comune è l’algoritmo di clustering K-means, che raggruppa i dati in base a somiglianze.

5. COS’È L’APPRENDIMENTO PER RINFORZO?
L’apprendimento per rinforzo si basa su un sistema di ricompense e penalità per migliorare le prestazioni del modello. Gli algoritmi agiscono come “agenti” autonomi e imparano a raggiungere obiettivi specifici attraverso tentativi ed errori. Ad esempio, nei giochi un agente può imparare a massimizzare il punteggio seguendo un insieme di regole e ricevendo dei feedback sul proprio rendimento. Fanno parte di questa categoria il Q-Learning e il Monte Carlo Tree Search (MCTS) la cui applicazione più famosa è Google AlphaZero.
6. COS’È IL DEEP LEARNING?
Il deep learning è una sottocategoria del machine learning che utilizza reti neurali artificiali per modellare e risolvere problemi complessi. Queste reti sono ispirate alla struttura del cervello umano e sono particolarmente efficaci nel riconoscimento di immagini, nel riconoscimento vocale e nella traduzione automatica.
7. COS’È UNA RETE NEURALE?
Una rete neurale artificiale è un algoritmo che imita il funzionamento del cervello umano per elaborare dati e prendere decisioni. È composta da nodi (neuroni) organizzati in strati. Le reti neurali sono alla base di molte applicazioni di deep learning, come il riconoscimento facciale e i veicoli autonomi.
8. COS’È LA CLASSIFICAZIONE E LA REGRESSIONE NEL MACHINE LEARNING?
Sia la classificazione che la regressione sono tecniche di apprendimento supervisionato:
- Classificazione: predice a quale categoria appartiene un dato. Ad esempio, determinare se un’email è spam o no.
- Regressione: predice un valore continuo. Ad esempio, stimare il prezzo di una casa in base alle sue caratteristiche.
9. COS’È IL SELECTION BIAS?
Il selection bias si verifica quando il campione di dati scelto per l’analisi non rappresenta adeguatamente la popolazione di interesse, portando l’analista a conclusioni errate. Facendo un esempio ovvio, se si volesse valutare lo stato di salute della popolazione di una città intervistando solo assidui frequentatori di palestre e centri sportivi, si otterrebbero risultati decisamente fuorvianti!
10. COS’È UNA MATRICE DI CONFUSIONE?
Una matrice di confusione è uno strumento utilizzato per valutare la performance di un algoritmo di classificazione. È una tabella che consente di visualizzare i risultati delle predizioni fatte da un modello confrontandole con i valori reali. La matrice di confusione è particolarmente utile per capire non solo la precisione generale del modello, ma anche per identificare specifici tipi di errori. Una matrice di confusione per un problema di classificazione binaria è una tabella 2×2 con le seguenti voci:
- True Positive (TP): Numero di esempi positivi correttamente classificati come positivi.
- False Positive (FP): Numero di esempi negativi erroneamente classificati come positivi.
- True Negative (TN): Numero di esempi negativi correttamente classificati come negativi.
- False Negative (FN): Numero di esempi positivi erroneamente classificati come negativi.
Immaginiamo di avere un set di dati con 100 esempi, dove 40 sono positivi e 60 sono negativi. Supponiamo che il modello produca i seguenti risultati:
| Predetto Positivo | Predetto Negativo | |
| Reale Positivo | 30 (Vero Positivo) | 5 (Falso Negativo) |
| Reale Negativo | 10 (Falso Positivo) | 55 (Vero Negativo) |
Dalla matrice di confusione è possibile calcolare diverse metriche di performance del modello, tra cui:
- Accuracy (Accuratezza): (TP + TN) / (TP + FP + TN + FN) = (30 + 55) / 100 = 0.85
- Precision (Precisione): TP / (TP + FP) = 30 / (30 + 5) = 0.86
- Recall (Sensibilità o TPR): TP / (TP + FN) = 30 / (30 + 10) = 0.75
- F1-Score: 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.86 * 0.75) / (0.86 + 0.75) ≈ 0.80
La matrice di confusione è estremamente utile perché fornisce una rappresentazione chiara di come il modello stia performando, consentendo di identificare non solo l’accuratezza generale, ma anche specifici errori (come i falsi positivi e i falsi negativi), il che è cruciale per molte applicazioni pratiche come la diagnosi medica, il rilevamento di frodi e molte altre aree. Ora è chiaro perché si chiama di confusione?
11. COS’È L’APPRENDIMENTO INDUTTIVO E DEDUTTIVO?
- Apprendimento Induttivo: il modello deriva regole generali da esempi specifici. Ad esempio, imparare le regole grammaticali da frasi osservate.
- Apprendimento Deduttivo: il modello applica regole generali a casi specifici per trarre conclusioni. Ad esempio, applicare regole matematiche per risolvere problemi specifici.
12. COS’È IL KNN E IL K-MEANS CLUSTERING?
- K-Nearest Neighbor (KNN): è un algoritmo di apprendimento supervisionato utilizzato principalmente per problemi di classificazione e regressione. Non costruisce un modello esplicito, ma memorizza tutti i casi di addestramento e fa le predizioni basandosi sulla vicinanza dei punti di dati nel set di addestramento.
- K-means Clustering: K-Means Clustering è un algoritmo di apprendimento non supervisionato utilizzato per raggruppare un set di dati in K gruppi (cluster). L’obiettivo è suddividere i dati in cluster tali che i punti all’interno di ogni cluster siano più simili tra loro rispetto ai punti appartenenti ad altri cluster.
13. COS’È LA CURVA ROC?
La curva ROC, acronimo di Receiver Operating Characteristic, è uno strumento grafico per valutare le prestazioni di un modello di classificazione, tracciando il tasso di veri positivi contro il tasso di falsi positivi. Un’area maggiore sotto la curva indica un modello migliore. Eccone un esempio:
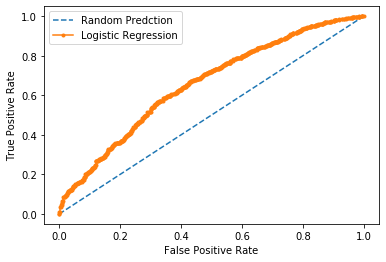
Interpretazione della Curva ROC:
- True Positive Rate (TPR), o sensibilità: TPR = TP / (TP + FN)
- False Positive Rate (FPR): FPR = FP / (FP + TN)
La curva ROC è tracciata mettendo “FPR” sull’asse X e “TPR” sull’asse Y. Un modello perfetto avrebbe una curva ROC che passa per il punto (0,1), indicando un alto TPR e un basso FPR. L’area sotto la curva ROC (AUC) è un indicatore della qualità del modello: un valore AUC di 1 rappresenta un modello perfetto, mentre un valore AUC di 0.5 indica un modello che non è migliore del caso.
14. QUAL È LA DIFFERENZA TRA ERRORE DI TIPO I E TIPO II?
- Errore di Tipo I (Falso Positivo): il modello prevede erroneamente che una condizione sia vera quando è falsa. Questo succede ad esempio, quando viene diagnosticata una malattia di cui il paziente non è affetto.
- Errore di Tipo II (Falso Negativo): il modello prevede erroneamente che una condizione sia falsa quando è vera. Ad esempio, non diagnosticare una malattia che è invece presente.
15. CHE COSA SONO I FALSI POSITIVI/NEGATIVI ?
Chiariamo con un esempio come si può rispondere a questa domanda. Immaginiamo di avere un modello che deve rilevare la presenza di una malattia (positivo) basandosi su un test diagnostico. I risultati possono essere espressi così:
- Vero Positivo (TP): Il test predice che la persona ha la malattia e la persona ha effettivamente la malattia.
- Falso Positivo (FP): Il test predice che la persona ha la malattia, ma la persona non ha la malattia.
- Vero Negativo (TN): Il test predice che la persona non ha la malattia e la persona effettivamente non ha la malattia.
- Falso Negativo (FN): Il test predice che la persona non ha la malattia, ma la persona ha effettivamente la malattia.
16. E’ PIU’ IMPORTANTE LA PERFORMANCE DEL MODELLO O LA SUA ACCURANCY?
L’accurancy del modello è parte integrante della sua performance. Se ad esempio dobbiamo identificare delle frodi da un database con una grande quantità di dati, aumentare la precisione dell’algoritmo (quindi trovare le transazioni truffaldine tra la moltitudine di transazioni innocue) permette di conseguenza di aumentarne le prestazioni finali.
Se ti è piaciuto questo articolo potresti apprezzare anche: “La Formula Magica della Ricchezza? Gli Interessi Composti“